Negative test cases that probe the limits of what an application can handle are among the most valuable tests we can conduct in software development. But while testing with invalid and corrupt data may seem straightforward, it’s an art form that requires deep planning, plenty of trial and error, and an openness to experimentation. And in 2024, with applications and systems more complex than ever, the stakes are higher too. This article digs into edge case testing with invalid and corrupt data, from strategies to examples, all while sharing some hard-earned insights.
Why Test with Invalid and Corrupt Data?
“Testing is a relentless pursuit of truth,” says James Bach. In the world of software, truth often surfaces when things go wrong, not when everything operates smoothly. Invalid and corrupt data scenarios expose weak spots in software, revealing how applications respond to unexpected input, data structure malfunctions, and outright misconfigurations.
✅ Definition of Invalid and Corrupt Data Testing:
Invalid data testing ensures that inputs that don’t meet system requirements are handled gracefully. Examples include fields with wrong formats, missing required values, or un-parseable special characters.
✅ Example Types of Invalid/Corrupt Data Scenarios:
- Invalid date formats like
2024-13-32 - Special characters in fields meant for numbers
- Overly long inputs or zero-byte files
Edge cases don’t just expose bugs; they can shine a spotlight on where systems fail to meet the real-world variability, they’re likely to encounter. And as testers in 2024, we have access to tools and techniques that allow us to explore these scenarios more fully than ever before.
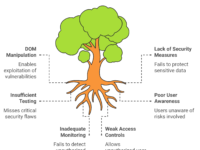
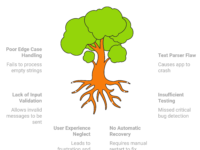
The Critical Strategies of Negative Testing in 2024
Here’s a mind map outlining a solid approach to structuring negative test cases:
Each of these branches represents an area to explore in edge testing. For example, by injecting “overflow” data or incomplete JSON, we observe how well the software’s data handling mechanics hold up. Let’s dive deeper into each.
1. Missing Fields and Empty Values
Most applications expect fields to follow a defined schema. But how does the application react when a field is empty or missing? This can be particularly enlightening in systems where every field is essential for operation.
- Example: In a registration form, leave out the password and email fields and attempt to submit the form.
- Expected Outcome: The system should reject the form and display a clear error message.
2. Invalid Formats
Data format validation is crucial, particularly for inputs like dates, email addresses, and numeric values. Improper validation or error handling in this area can lead to security issues, unexpected crashes, and a poor user experience.
- Example: Submitting a birthday as “April 35, 2024” or an email address as “name@do****@*****er.com”.
- Pain Point: Sometimes, data validation is pushed to the database, causing potential failure points. Identifying these is vital.
3. Overflow and Underflow Testing
Overflow is another critical scenario where systems can buckle, particularly in fields that assume an upper limit. In 2024, as applications handle more user data and larger inputs, overflow vulnerabilities can lead to buffer overflow attacks or service failures.
- Example: Attempt to upload a file larger than the expected size or input a 1000-character password.
- Pain Point: Without clear limits, applications might crash, or worse, provide attackers with entry points.
4. Malformed JSON and XML
Corrupt data formats, like malformed JSON or XML, are increasingly relevant as systems integrate via APIs. Imagine sending a half-closed JSON object to an API endpoint: this is the type of scenario where systems that don’t handle unexpected data well can easily fail.
- Example Code Snippet (Python):
import json
# Malformed JSON example
json_data = '{"user": "test", "age": 25, "email": "te**@*****le.com",'
try:
data = json.loads(json_data)
except json.JSONDecodeError as e:
print("Caught JSON Decode Error:", e)
- Expected Outcome: The system should throw a decoding error and handle it gracefully, possibly logging the issue or notifying the user.
Major Pain Points and Criticisms in 2024 🌐
While edge testing is critical, it’s not without its challenges. Here are a few notable pain points we face today:
- Unpredictable Behavior in Systems with AI and ML: As AI and ML integration in systems grow, the variability of invalid inputs is hard to predict. Sometimes, the very edge case we’re testing could train the system to handle that input better next time—making traditional edge cases less reliable.
- Time and Cost: Testing every potential corrupt data combination can be impractical. The sheer volume of data variation makes it difficult to prioritize, especially in agile environments where time is a constraint.
- Tool Limitations: While there are tools like Postman and SoapUI for testing APIs with invalid data, they often lack built-in mechanisms for generating diverse corrupt data automatically. The manual setup of these tests can consume time.
A Critical Look: The Pros and Cons of Current Tools ⚖️
Here’s a breakdown of some popular tools for edge case testing in 2024 and their capabilities:
| Tool | Features | Limitations |
|---|---|---|
| Postman | API testing, some data gen. | Limited invalid data automation |
| SoapUI | SOAP/REST testing | Manual corrupt data injection required |
| JMeter | Load testing | Not optimized for invalid edge cases |
| Fuzzing Tools | Random data gen. | Rarely target structured JSON/XML |
Given the limitations of mainstream testing tools, there’s a noticeable gap in tools designed for comprehensive invalid data testing. This gap can sometimes make it feel like we’re fighting against the tide when performing edge case testing.
Practical Bottlenecks in Edge Testing
To give you a clearer picture, here are two real bottlenecks you might encounter in edge case testing:
- Database Integrity Issues
When invalid or corrupt data reaches the database, it can lead to data inconsistency, failed transactions, and sometimes even database corruption. Testing for this requires setting up environments where both application and database behaviors are monitored. - Logging and Error Monitoring
Many applications fail silently when they encounter invalid data, especially at the integration points. For edge testing to be meaningful, having a robust logging and monitoring mechanism is essential, so you can identify exactly where and why failures occur.
Conclusion: What’s Next for Edge Case Testing?
To get the most out of invalid and corrupt data testing, we need a nuanced approach, combining traditional edge case scenarios with updated tools and methods that align with our 2024 tech landscape. Testing, after all, isn’t about perfection but about exposing the fragility of our assumptions and software boundaries.
For those interested in exploring deeper, I recommend checking out this article on structured edge case design or give a look at this GIT repo on fuzz testing at FuzzTest.
In an age where software systems need to be resilient and adaptable, negative testing with invalid and corrupt data remains essential—yet it’s also evolving. And as testers, we’re uniquely positioned to embrace these challenges and refine the process for the next wave of innovation. Happy testing! 🎉