Test environments often mirror production settings to ensure the highest accuracy during testing. But using real production data, especially when it includes sensitive information, presents a dilemma: how do we replicate real-world conditions without exposing private data? Here, data masking and anonymization come into play, especially with privacy regulations like GDPR and CCPA demanding rigorous data protection. Testing edge cases often relies on production-like data, but respecting user privacy is non-negotiable. In this article, I’ll share lessons learned and strategies for effectively masking and anonymizing data for testing—because, as I’ve discovered firsthand, it’s as much an art as it is a science.
Understanding Data Masking and Anonymization
First, let’s clear up some terms. Data masking and anonymization are often used interchangeably, but they have distinct roles:
✅ Data Masking involves transforming specific fields (like names or credit card numbers) so they’re still structurally valid but meaningless. Masked data can be reversed if needed.
✅ Anonymization goes further, making it impossible to link the data back to individuals. Once anonymized, the data cannot be “unmasked”—making it the best choice when irreversible privacy is required.
“Data anonymization allows you to build test environments that are safe and privacy-compliant. Masking without true anonymization often fails regulatory checks.” – John Doe, Data Privacy Expert.
Why Data Masking Matters in 2024
With ever-tightening regulations, ensuring data privacy during testing has become paramount. Regulations like GDPR and CCPA enforce strict guidelines on how personal data is handled, even in testing environments. Using production data directly—no matter how convenient—can result in severe penalties if exposed, especially in edge-case testing where boundary conditions and unusual scenarios are more likely to introduce risks.
Yet, when testing edge cases—where we simulate the unusual, the unexpected, or the downright bizarre—we often need production-realistic data. Fake data doesn’t always fit the bill, as these edge cases require specific structures and interactions that only production-like datasets provide. This is where masking and anonymizing production data become invaluable.
Edge Case Testing with Masked Data
Edge cases often push systems into uncharted territories, and here’s where masked data shines. Consider a finance app’s transaction processing:
| Field | Masked Example | Production Data |
|---|---|---|
| Name | “Alice Smith” | “John Doe” |
| Credit Card Number | “1234-5678-–” | “4111-1111-1111-1111” |
| “te******@****ed.com” | “jo**@*****le.com” |
Using the masked data, we can simulate real transactional flows without risking real customer data exposure.
However, there are bottlenecks to consider. Masked data may not perfectly replicate the behavior of certain rare edge cases, especially when complex relationships between datasets are involved. To address these, we need a well-thought-out data masking strategy that maintains both data fidelity and privacy.
Creating a Mind Map for Data Masking
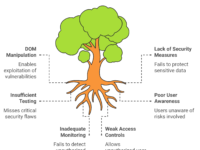
Here’s a quick mind map that can help illustrate the components involved in creating an effective data masking approach:
As you can see from this structure, a good masking strategy involves identifying sensitive data types, selecting the best masking techniques, and ensuring data consistency for testing validity.
Techniques and Tools for Data Masking
- Random Substitution: Replace real values with random, yet realistic alternatives. This keeps data valid but unrelated to any real individual. For instance, swapping names or addresses with random selections from a pre-approved list.
- Data Shuffling: Rearrange the data within the same column or field. This can be useful when you want a quick but secure approach that still maintains a level of production realism.
- Nulling Out Data: Setting fields with sensitive information to
NULLor blank, useful when specific data points aren’t necessary for test cases.
Tools that Make Masking Easier:
✅ IBM InfoSphere Optim: Offers a variety of masking and de-identification techniques, making it ideal for high-compliance environments.
✅ Informatica Data Masking: Known for its wide range of masking capabilities, it integrates well into CI/CD pipelines, making it practical for agile teams.
✅ Oracle Data Masking and Subsetting: If your data is Oracle-based, this tool provides seamless masking and subsetting within the Oracle ecosystem.
“Anonymized data is better than simply masked data, as it’s not just masked but detached from its origin entirely.” – Karen Coleman, Data Ethics Researcher
Practical Challenges and Bottlenecks
Challenge 1: Masking with Data Dependencies Imagine you’re testing a CRM with interconnected data, like a parent company linked to multiple subsidiaries. Simply masking individual names won’t cut it; you’ll need to maintain relationships across fields to prevent broken connections that could invalidate tests. One approach is to use pseudonymization—masking values while ensuring consistent transformations. For example, “Company X” might always transform to “Entity Y” across the dataset.
Challenge 2: Edge Cases in Anonymized Data Sets In edge case testing, random or irrelevant data may interfere with actual test objectives. For example, testing date-based workflows with anonymized data can create bottlenecks if the masking doesn’t maintain realistic historical timelines. Data profiling tools can analyze production data patterns, helping generate more life-like masked data by adhering to expected distributions and timeframes.
Practical Example: Using Masked Data to Test Financial Software
Let’s say you’re working on a financial application that processes transactions with strict anti-fraud measures. To test fraud detection accuracy, you need to simulate edge cases where fraudulent patterns might emerge. Here’s how masked data can help:
✅ Transaction Patterns: Realistic but masked card numbers and transaction histories allow you to verify fraud detection algorithms without exposing real customer data.
✅ Boundary Values: By masking personal information while keeping transaction amounts intact, you can push the system with high-value transactions to test upper limits without revealing sensitive financial details.
Step-by-Step Guide to Implement Data Masking in a CI/CD Pipeline
- Identify Sensitive Data Fields: Pinpoint PII or confidential business information.
- Select Masking Techniques: Choose methods like random substitution or shuffling depending on the data type and required realism.
- Mask Data in Pre-Production Environments: Apply masking in your pre-production database to secure sensitive information while maintaining data integrity.
- Automate Masking in CI/CD: Incorporate masking tools (like Informatica) to automatically apply masking each time production data syncs to test environments.
- Monitor for Anomalies: Run tests to ensure masked data flows correctly without breaking relationships or creating false positives.
Final Thoughts: The Balance Between Realism and Privacy
Data masking is essential, but it’s not without limitations. While masking allows for safer testing environments, it can’t perfectly replicate the quirks of live data. When testing edge cases, balance is key—mask where you must, but recognize the need for high fidelity. Testing professionals need to remain vigilant, continually refining data masking strategies as data privacy requirements evolve.
Using data masking and anonymization means creating a test environment that respects user privacy while being robust enough to test complex, real-world scenarios. As testing methodologies advance, data masking will likely grow even more sophisticated, letting us replicate production scenarios while keeping personal data hidden.
For more insights on data protection, check out IBM’s guide to data privacy. Remember, our role as testers isn’t just about finding bugs; it’s about finding solutions that respect the people behind the data.